LLM을 처음 써보면서 모델 이름과 입력 텍스트만 보냈었고,
조금 더 정밀하게 답변을 제어하고 싶어서 옵션을 추가해봤었습니다.
이전 프로젝트:
https://devbrew.tistory.com/120
[Next.js] 개인 프로젝트 - AI 원두 설명기 제작 (1)
저는 카페를 참 좋아하고, 필터 커피를 좋아하고, 원두 설명지 보는 것을 좋아하는데요.원두가 이름과 설명이 복잡하다보니 주변에서 필터 커피 자체를 어렵게 느끼는 분들이 많았고,메뉴판에
devbrew.tistory.com
직접 만든 커피 원두 설명기 프로젝트에서도 답변이 매번 달라지고 길이도 제각각이었는데
옵션을 적절하게 추가해주니 원하는 답변을 비교적 일관되게 받을 수 있었죠.
이번 글에서는 Responses API 를 기준으로,
앞으로도 자주 사용할법한 기초 옵션들을 사용해보고 정리해보았습니다.
1. 기본 호출 예시
// OpenAI API 호출 예시
const resp = await client.responses.create({
model: "gpt-4o-mini",
input: [
{ role: "system", content: "답변은 4문장으로 요약해 줘" },
{ role: "user", content: prompt },
],
// 옵션은 이 자리에 들어갑니다 !
});
실험 환경은 Next.js이며 OpenAI의 gpt-4o-mini 모델을 사용했습니다.
실험을 위해 이전 프로젝트에서 만들었던 "AI 커피 원두 설명기"의 모든 규칙을 삭제하고,
"답변은 4문장으로 요약해 줘" 라는 규칙만 추가한 상태에서 테스트를 진행했습니다.
2. 주요 옵션 실험
(1) temperature
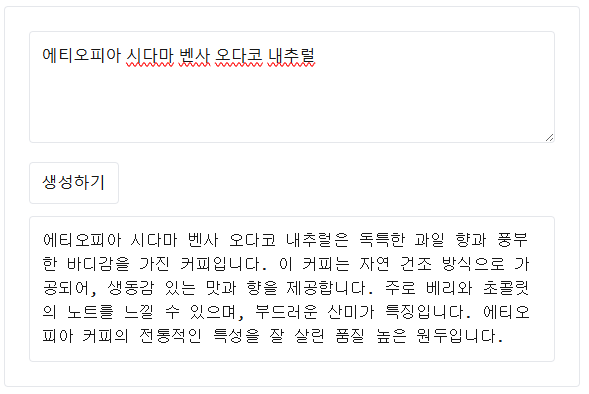
temperature 는 창의성 조절 옵션으로 0 ~ 2 까지 설정이 가능합니다.
temperature: 0 일 때는 여러번 시도해도 왼쪽 사진의 내용으로 동일한 답변만 반복됬습니다.
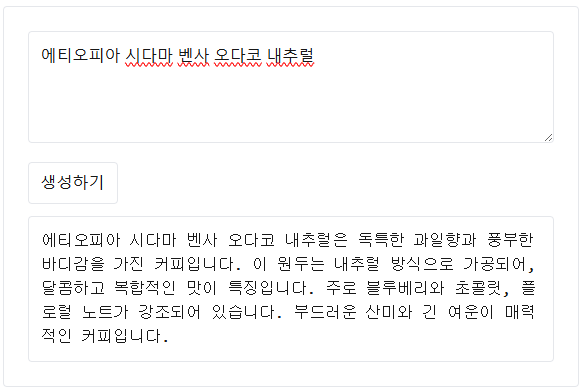
temperature: 1 로 수정하니 오른쪽 사진처럼 답변 내용이 조금 달라졌는데 살펴보면
맛 표현이 바뀌고 품질 설명이 빠진 것을 확인할 수 있었습니다.
0 ~ 1 사이에서 적절한 값을 넣고, 표현하고 싶은 항목을 규칙에서 명확하게 정해준다면
적당히 일관적이고 다양한 표현의 설명을 받을 수 있을 것 같다는 느낌을 받았습니다.
temperature 를 1 이상으로 올리는 건 주의가 필요해보였습니다.

temperature: 2 에서는 의미 없는 문자들이 나오는 경우가 자주 발생했습니다.
창의성을 넘어 엄청난 양의 문자가 나오니 순식간에 토큰 사용량이 폭증했습니다.
이는 갑작스러운 비용 증가로 이어질 수 있는 만큼 주의가 필요해보였습니다.
(2) max_output_tokens

max_output_tokens 는 말 그대로 모델이 사용할 토큰 수의 최대 값을 지정합니다.
불필요하게 긴 답변을 방지하고, 비용을 관리할 수 있습니다.
긴 답변을 방지하는 것에서 앞서 system 에서 "4문장으로 요약"을 요청한 것과 다르게,
답변의 길이가 초과되면 사진처럼 잘리도록 되어있는게 차이입니다.
수치를 너무 작게 잡으면 문장이 중간에 끊겨버릴 수 있기 때문에
목적에 맞게 여러번 실행해보면서 안전한 범위에서 넉넉하게 정하면 될 것 같습니다.
(3) top_p

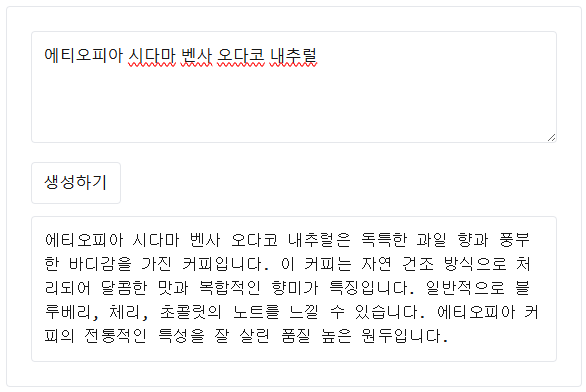
top_p 옵션은 답변의 후보군을 제한하는 옵션으로 개인적으로 어려웠지만 신기했는데요.
모델이 다음 단어(토큰)를 고를 때, 가능한 모든 후보에 확률이 매겨집니다.
top_p 는 이 확률들을 큰 순서로 합산해 지정한 값에 도달할 때까지의 후보만 남기는 방식입니다.
예를 들어서 [독특한 과일 향과 풍부한 바디감]이라는 표현을 생성할 때,
모델은 [과일], [열매], [과실] 같은 단어를 후보로 두고 여러가지 기준으로 연관성과 관련된 확률을 매깁니다.
그리고 확률들을 높은 것부터 차례대로 합산을 하여 후보군을 어디까지 포함할지를 정하는 것입니다.
top_p: 1.0 은 모든 후보를 고려하는 것이라면,
top_p: 0.9 는 확률이 낮은 일부 후보를 제외한 상위 90% 후보군만 고려하는 것이죠.
temperature 가 후보군에 대한 확률에 변동성을 주어 창의성을 만드는 옵션이라면,
top_p 는 후보군 자체를 잘라내서 선택지를 제한하는 옵션이라고 볼 수 있겠습니다.
(쉬운 설명을 위해 단어라고 표현했지만, 실제로는 토큰 단위입니다.)
이처럼, LLM 옵션은 단순한 기능이 아니라,
모델의 성격과 답변 스타일을 서비스 목적에 맞게 조율하는 도구라고 볼 수 있습니다.
사실 이번 실험만으로 아주 큰 차이를 체감한 것은 아니지만,
모델이 처리해야할 데이터가 많아지고 서비스의 요구사항이 다양해질수록,
분명 이런 옵션들이 실제 결과 품질과 비용에서 큰 차이를 만들 것이라 생각합니다.
저도 이 부분에서는 계속 공부하고, 앞으로 더 다양한 옵션과 사례를 정리해보겠습니다 !